robots.txt写法详解与注意事项
一、robots.txt的用途
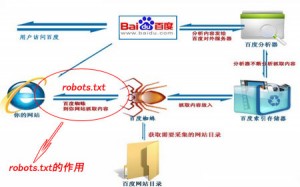
robots.txt写法详解及注意事项
一个网站中有很多个文件,其中包含了后台程序文件、前台模板文件、图片等等。这之中有一些东西我们是不希望被百度蜘蛛抓取的,怎么办呢?搜索程序考虑到了这一点,蜘蛛在抓取网站页面之前会先访问网站根目录下的robots.txt文件,如果此文件存在那么按照robots.txt限定的范围进行抓取,如果不存在,则默认为可以抓取全部。
二、robots.txt在seo中在作用
百度一个页面抓取的两个网址,这样会分散网页的权重,如果我们写好robots.txt就可以避免这样的情况产生。robots.txt在seo中在作用就是屏蔽不必要的页面抓取,为有效页面赢得蜘蛛抓取的机会。由于屏蔽不必要页面抓取从而可以提高页面权重,节省网络资源;最后我们可以将网站地图放在里面,方便蜘蛛抓取网页。
三、哪些文件是可以用robots.txt屏蔽的
网页中的模板文件、样式表文件以及后台的某些文件即使被搜索引擎抓取了也没什么作用,反而是浪费网站资源,这类文件可以屏蔽;
某些特定页面比如联系我们、公司内部某些不需要公开的照片这些都可以根据实际情况进行屏蔽。
四、robots.txt写法详解及注意事项
以主机博客为例,robots.txt文件如下:
User-agent:*这样的记录只能有一条。*代表所有引擎蜘蛛,如果仅仅只针对某个搜索引擎可以这样写果User-agent:Baiduspider表示只下面规则都是针对百度蜘蛛的。
Disallow: 描述不需要被索引的网址或者是目录。比如Disallow:/wp-不允许抓取url中带wp-的网址;要注意的是Disallow: /date/与Disallow: /date是不一样的;前者仅仅是不允许抓取date目录下的网址,如果data目录下还有子文件夹,那么子目录是允许抓取的,后者可以屏蔽date目录下所有文件,包括起子文件夹。
Allow:描述不需要被索引的网址或者是目录。功能跟disallow相反,特别注意的是Disallow与Allow行的顺序是有意义的,robot会根据第一个匹配成功的Allow或Disallow行确定是否访问某个URL。
使用”*”和”$”:Baiduspider支持使用通配符”*”和”$”来模糊匹配url。”$” 匹配行结束符。”*” 匹配0或多个任意字符。
robots文件创建以后,可以使用谷歌管理员工具进行测试,确保robots.txt书写正确这样才能起到效果。