вЛЁЂpythonжаЮФБрТыЮЪЬт
ЕБзжЗћДЎЪЧЃК'u4e2du56fd'
ЕБзжЗћДЎЪЧ:' ЖЋбЧбЇЭХвЛжа'
ord()жЇГжunicodeЃЌПЩвдЯдЪОЬиЖЈзжЗћЕФunicodeКХТыЃЌШчЃК
жЛвЊКЭUnicodeСЌНгЃЌОЭЛсВњЩњUnicodeзжДЎЁЃШчЃК
ЖдгкASCII(7ЮЛ)МцШнЕФзжДЎЃЌПЩКЭФкжУЕФstr()КЏЪ§АбUnicodeзжДЎзЊЛЛГЩASCIIзжДЎЁЃШчЃК
ЖдМИИіИХФюЕФРэНтЃК
ASCIIТы гУЪ§Онзж ЖдгІ ЯргІЕФзжЗћ ШчЯТЭМЫљЪОЃК
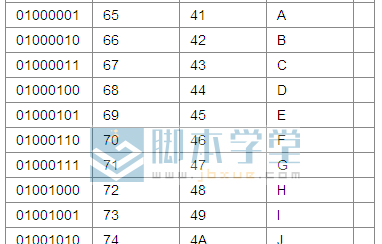
ЖјжаЮФ ОЭЪЧЧјЮЛТыЖдгІККзжЁЃШчЃК“КУ” ЕФASCIIТыЮЊЃК 22909
unicode БрТы УПИіЙњМвЗжвЛПщЁЃЫќгаUTF-8ЁЂUTF-16ЁЂUTF-32ЕШаЮЪН
жаЮФЗЖЮЇ 4E00-9FBFЃКетИіЗЖЮЇФкга gbk,gb2312,
utf-8ЪЧЛљгкunicodeЕФ ЙњМЪЛЏЕФГЁКЯЪЪКЯЪЙгУ
gb2312КЭgb2312ЖМЪЧЙњБъТы ГіЯжЕФНЯдч жївЊгУгкБрНтТыГЃгУККзжЁЃ
----------------------------------------
ЪзЯШЃЌвЊУїАзencode()КЭdecode()ЕФЧјБ№
encode()ЕФзїгУЪЧНЋUnicodeБрТыЕФзжЗћДЎзЊЛЛЮЊЦфЫћБрТыИёЪНЁЃ
Р§ШчЃК
st1.encode("utf-8") етОфЛАЕФзїгУЪЧНЋUnicodeБрТыЕФst1БрТыЮЊutf-8БрТыЕФзжЗћДЎ
decode()ЕФзїгУЪЧАбЦфЫћБрТыИёЪНЕФзжЗћДЎзЊЛЛГЩUnicodeБрТыЕФзжЗћДЎЁЃ
Р§ШчЃК
st2.decode("utf-8") етОфЛАЕФзїгУЪЧНЋutf-8БрТыЕФзжЗћДЎst2НтТыЮЊUnicodeБрТыЕФзжЗћДЎ
ЕкЖўЃЌГ§UnicodeБрТыЕФзжЗћДЎвдЭтЃЌШЮКЮвЛжжБрТыЕФзжЗћДЎвЊЯызЊЛЛЮЊЦфЫћБрТыИёЪНЃЌБиаыЯШНтТыКѓБрТы
ЗЧUnicodeБрТы--> UnicodeБрТы-->ЗЧUnicodeБрТы
Р§ШчЃЌutf-8БрТыЕФзжЗћДЎstЯывЊзЊЛЛЮЊgbkБрТыЕФзжЗћДЎЃЌБиаыОЙ§вдЯТВНжшЃК
ЕкШ§ЃЌОГЃЪЙгУЕФutf-8БрТыЛЙЗжЮЊгаBOMЕФКЭЮоBOMЕФЁЃ
ЕкЫФЃКЙигкjsonЮФМўЕФжаЮФБрТыЁЃгУPythonЖСШЁJsonЮФМўЪБОГЃгУЕНjson.load()КЏЪ§ЃЌИУКЏЪ§ЖдjsonЮФМўЕФИёЪНЪЧгавЊЧѓЕФ
1ЃЉjsonЮФМўЪЧutf-8 without BOMБрТыЕФ,ФЧУДПЩвджБНггУjson.load(filename)КЏЪ§ЖСШЁjsonЮФМўЕФФкШн
2ЃЉjsonЮФМўЪЧutf-8 with BOMБрТыЕФЃЌВЛФмгУjson.load()КЏЪ§ЖСШЁЃЌjson.load()ВЛФме§ШЗЪЖБ№
3ЃЉjsonЮФМўЪБЦфЫћБрТыЕФЃЌБШШчgbk, вЊАбjsonЮФМўЕФБрТыИёЪНзїЮЊвЛИіВЮЪ§ДЋИјjson.load()ЃК
eg. json.load(filename,"gbk")
ЕкЮхЃЌдѕУДВщПДВЂЧвЩшжУздМКЮФМўЕФБрТыФиЃП
НщЩмвЛИіИіШЫБШНЯЯВЛЖЕФЙЄОп"Nodtepad++"ЃЌЫцБувЛИіШэМўЙмМвРяОЭгывЛМќАВзАЁЃ
гУетИіЙЄОпФуПЩвдЗНБуЕФВщПДздМКЕФЮФМўЕФЕБЧАБрТыЃЌВЂПЩвдЧсЫЩзЊЛЛГЩШЮвтЦфЫћБрТыИёЪН
---------------
ЖўЁЂpythonДІРэжаЮФБрТыКЭХаЖЯБрТыЕФЗНЗЈ
дкПЊЗЂздгУХРГцЙ§ГЬжаЃЌгаЕФЭјвГЪЧutf-8ЃЌгаЕФЪЧgb2312,гаЕФЪЧgbkЃЌШчЙћВЛМгДІРэЃЌВЩМЏЕНЕФЖМЪЧТвТыЃЌНтОіЗНЗЈЪЧНЋhtmlДІРэГЩЭГвЛЕФutf-8БрТы
еыЖдpython2.7
#coding:utf-8
#chardet ашвЊЯТдиАВзА
import chardet
#зЅШЁЭјвГhtml
line = "http://www.***.com"
html_1 = urllib2.urlopen(line,timeout=120).read()
#print html_1
encoding_dict = chardet.detect(html_1)
#print encoding
web_encoding = encoding_dict['encoding']
if web_encoding == 'utf-8' or web_encoding == 'UTF-8':
html = html_1
else :
html = html_1.decode('gbk','ignore').encode('utf-8')
#гавдЩЯДІРэЃЌећИіhtmlОЭВЛЛсЪЧТвТыЁЃ