大多数SQL Server 表需要索引来提高数据的访问速度,如果没有索引,SQL Server 要全表进行扫描读取表中的每一个记录才能找到所要的数据。
索引可以分为簇索引和非簇索引:簇索引通过重排表中的数据来提高数据的访问速度;而非簇索引则通过维护表中的数据指针来提高数据的访问速度。
1. 索引的体系结构
SQL Server 2005 在硬盘中用 8KB 页 面在数据库文件内存放数据。缺省情况下这些页面及其包含的数据是无组织的。为了使混乱变为有序,就要生成索引。生成索引后,就有了索引页和数据页之分:数 据页用来保存用户写入的数据信息;索引页存放用于检索列的数据值清单(关键字)和索引表中该值所在纪录的地址指针。索引分为簇索引和非簇索引,簇索引实质 上是将表中的数据 排序,就好像是字典的索引目录。非簇索引不对数据排序,它只保存了数据的地址 。向一个带簇索引的表中插入数据,当数据页达到 100% 时,由于页面没有空间插入新的的纪录,这时就会发生分页, SQL Server 将大约一半的数据从满页中移到空页中,从而生成两个1/2满页。这样就有大量的空的数据空间。簇索引 是 双向链表,在每一页的头部保存了前一页、后一页以及分页后数据移出的地址。由于新页可能在数据库文件中的任何地方,因此页面的链接不一定指向磁盘的下一个 物理页。链接可能指向了另一个区域,这就形成了分块,从而减慢了系统的速度。对于带簇索引和非簇索引的表来说,非簇索引的关键字是指向簇索引的,而不是指 向数据页的本身。
为了克服数据分块带来的负面影响,需要重构表的索引,这是非常费时的,因此只能在需要时进行。 可以通过 DBCC SHOWCONTIG 来确定是否需要重构表的索引。
2. DBCC SHOWCONTIG 用法
下面举例来说明 DBCC SHOWCONTIG 和 DBCC REDBINDEX 的使用方法。以 应用程序中 的 Employee 数据 表 作为例子 ,在 SQL Server 的 Query analyzer 输入命令:
输出结果:
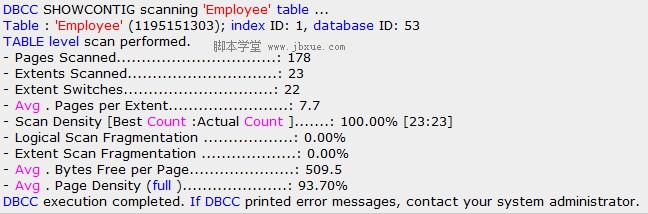
通过分析这些结果可以知道该表的索引是否需要重构。
如下描述了每一行的意义:
从上面命令的执行结果可以看的出来, Best count 为 23 而 Actual Count 为 25。 这表明 orders 表有分块,需要重构表索引。下面通过 DBCC DBREINDEX 来重构表的簇索引。
3 . DBCC DBREINDEX 用法
重建指定数据库中表的一个或多个索引。
语法
参数
database.owner.table_name
是要重建其指定的索引的表名。 数据库、所有者和表名必须符合标识符的规则。有关更多信息,请参见使用标识符。 如果提供 database 或 owner 部分,则必须使用单引号 (') 将整个 database.owner.table_name 括起来。如果只指定 table_name ,则不需要单引号。
index_name
是要重建的索引名。 索引名必须符合标识符的规则。 如果未指定 index_name 或指定为 ' ' ,就要对表的所有索引进行重建。
fillfactor
是创建索引时每个索引页上要用于存储数据的空间百分比。 fillfactor 替换起始填充因子以作为索引或任何其它重建的非聚集索引(因为已重建聚集索引)的新默认值。如果 fillfactor 为 0 , DBCC DBREINDEX 在创建索引时将使用指定的起始 fillfactor 。
同样在 Query Analyzer 中输入命令:
然后再用 DBCC SHOWCONTIG 查看重构索引后的结果:
通过结果我们可以看到 Scan Denity 为 100% 。