sql server 2005函数Row_Number
通常,开发者和管理员在一个查询里,用临时表和列相关的子查询来计算产生行号。
现在SQL Server 2005提供了一个函数,代替所有多余的代码来产生行号。
假设有一个资料库[EMPLOYEETEST],资料库中有一个表[EMPLOYEE],可以用下面的脚本来产生资料库,表和对应的数据。
USE [MASTER]
GO
IF EXISTS (SELECT NAME FROM SYS.DATABASES WHERE NAME = N'EMPLOYEE TEST')DROP DATABASE [EMPLOYEE TEST]
GO
CREATE DATABASE [EMPLOYEE TEST]
GO
USE [EMPLOYEE TEST]
GO
IF EXISTS SELECT * FROM SYS.OBJECTS HERE OBJECT_ID = OBJECT_ID(N'[DBO].[EMPLOYEE]') AND TYPE IN (N'U'))
DROP TABLE [DBO].[EMPLOYEE]
GO
CREATE TABLE EMPLOYEE (EMPID INT, FNAME VARCHAR(50),LNAME VARCHAR(50))
GO
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (2021110, 'MICHAEL', 'POLAND')
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (2021110, 'MICHAEL', 'POLAND')
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (2021115, 'JIM', 'KENNEDY')
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (2121000, 'JAMES', 'SMITH')
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (2011111, 'ADAM', 'ACKERMAN')
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (3015670, 'MARTHA', 'LEDERER')
INSERT INTO EMPLOYEE (EMPID, FNAME, LNAME) VALUES (1021710, 'MARIAH', 'MANDEZ')
GO
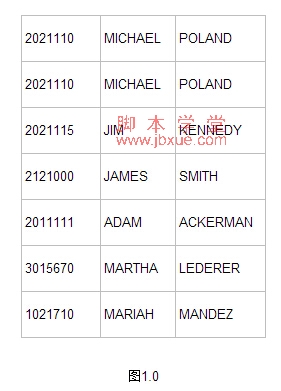
可以使用脚本查询EMPLOYEE表:
SELECT EMPID, RNAME, LNAME FROM EMPLOYEE
这个查询的结果应该如图1.0
SQL Server 2005,要根据这个表中的数据产生行号,通常使用如下查询:
此查询创建了一个新的表,用identify函数来产生行号。
查看表数据:
查询结果如图1.1
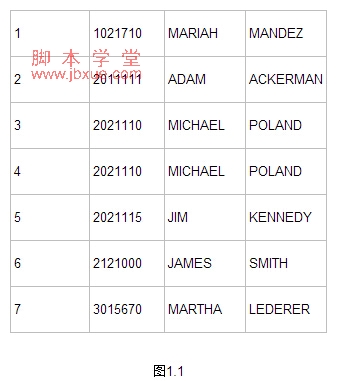
很明显EMP=2021110的行是重复的数据。
要删除EMPID=2021110的重复数据,我们必须在EMPLOYEE2表中删除,不能直接在EMPLOYEE中删除。
SQL Server 2005提供了一个新的函数(Row_Number())来产生行号。我们可以使用这个新函数来删除原来表中的重复数据,只用通常的表达方式再加上Row_Number()函数。
用Row_Number()函数根据EMPID来产生ROWID。
上面的查询结果如图1.2
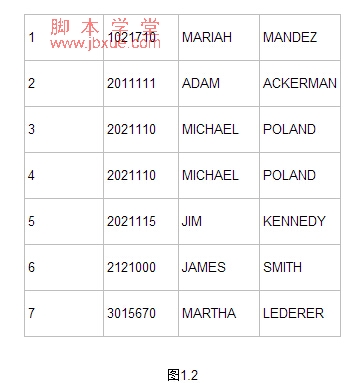
以上结果中,可以区别EMPID是2021110的重复数据。
可以用通用表查询表达式和Row_Numner()函数来选出重复的那行数据。
上面的查询结果如图1.3

这一行重复的数据可以用下面这个通用表和Row_Number()函数来删除。
删除以后,可以用下面的查询语句查看结果。
SELECT * FROM EMPLOYEE
查询结果如图1.4
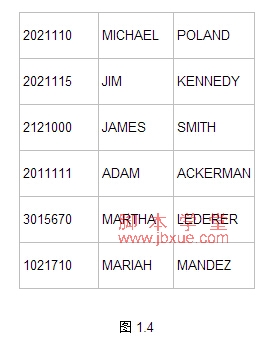
重复的数据已经被删除了。
以上讨论了SQL Server 2005 的新特性Row_Number()函数,还有通常的表表达式,然后如何使用这两个来删除重复的行。
如果需要删除大量重复数据时,可以使用如下脚本:
如果数据量超大时,建议不要使用通用表达式,通用表达式的效率远比临时表要低很多。