1、进行多张表连接,在数据库中先做了一个视图,把表连接起来。
(但是这样查询速度和直接在sql语句中写表连接差不多,但是如果把表连接写在视图中,程序中的sql语句将变得简洁,思路更清晰)
建立视图的sql语句如下:视图名为searchJCR
2、在程序中使用传统方法进行分页。
问题,使用的视图查询出来的结果又很多JournalID重复的记录,这样使用JournalID进行分页就不可行了。
因此,需要为每一条查询记录指定唯一一个标识,在oracle中有伪列rowid,可以用于区分每一条记录,在sql server2005之前,没有办法区分,但是在sql2005之后,提供了一个ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)函数用于实现类似于伪列的效果。
3、在程序中使用row_number()over()进行分页。
sql语句:
查询速度很慢。
优化(CTE,关于CTE的介绍将读者参阅《SQL Server2005杂谈(1):使用公用表表达式(CTE)简化嵌套SQL》),优化后的代码:
with t_rowtable
as
(
select row_number()over(order by YearNum DESC,JournalID ASC) as row_number,* from [JournalDB].[dbo].[searchJCR] where 1=1
)
select * from t_rowtable where row_number>100
and row_number <= 60000
row_number函数的用途是非常广泛,这个函数的功能是为查询出来的每一行记录生成一个序号,生成的机制是,按over(排序条件)中的排序条件对每条记录顺序生成一个rowid,然后将记录按select的order by顺序显示出来。
其中“where row_number>100
and row_number <= 60000” 可以用来控制每页的显示的记录,可以用来分页,“where row_number>(page-1)*pageSize
and row_number <= page*pageSize”,并且只需要将筛选记录的条件拼接在where 1=1之后,这样即使上十几万的数据都可以在3s中之内查询出来,效率很高。
例如:
row_number列是由row_number函数生成的序号列。在使用row_number函数是要使用over子句选择对某一列进行排序,然后才能生成序号。
实际上,row_number函数生成序号的基本原理是先使用over子句中的排序语句对记录进行排序,然后按着这个顺序生成序号。over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同,SQL语句:
sql分页查询结果:
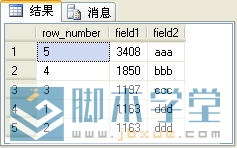
注意,如果将row_number函数用于分页处理,over子句中的order by 与排序记录的order by 应相同,否则生成的序号可能不是有续的。