НщЩмЯТMySQLжаЕФorder byгяОфЁЃ
МИжжorder byЕФЧщПі
ДгзюМђЕЅЕФcaseПЊЪМПДЦ№ЁЃ
гУетИіБэРДЫЕУїЃК(10wааЪ§Он)
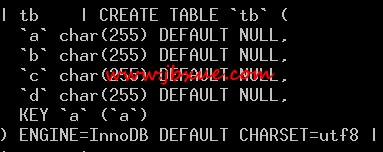
1ЁЂ зюМђЕЅЕФorder ЈDЈD order byЫїв§зжЖЮ

ДгexplainЕФНсЙћРДПДЃЈExtraСаЃЉЃЌетИігяОфВЂВЛзїХХађЁЃвђЮЊзжЖЮaвбОЪЧгаЫГађЕФЁЃОЭЪЧАДееЫїв§aЕФЫГађвРДЮЖСpkЕФжЕ(дкетРяЪЧвўВиЕФЯЕЭГСа)ЃЌвЛИіИіДгОлДиЫїв§ЕФdataжаЖСШыЁЃ
2ЁЂ ИДдгвЛЕу ЈDЈD order by ЗЧЫїв§зжЖЮ

етРяExtraСаЯдЪОвЛИіUsing filesortЁЃетРяЕФfilesortВЂВЛЪЧжИзжУцЩЯЕФ“ЮФМўХХађ”ЃЌЫЕЕФОЭЪЧгыЩЯУцвЛжжЧщПіЯрБШЃЌдкServerВузїСЫХХађЁЃжСгкЪЧЗёЪЙгУЮФМўЃЌШЁОігкХХађЙ§ГЬжаЕФФкДцЪЧЗёзуЙЛЃЌВЛЙЛдђашвЊСйЪБЮФМўЁЃ
serverВувЊдѕУДзїХХађФиЃП
вЛИіМђЕЅЕФЯыЗЈЪЧАбБэЪ§ОнЖМЖСЕНФкДцЃЌШЛКѓХХађЁЃЖСЕНФкДцЕБШЛПЩвдЯыдѕУДећОЭдѕУДећЁЃЕЋЪЧетИізіЗЈКмКФЗбФкДцЁЃашвЊеМгУгыБэвЛбљДѓаЁЕФФкДцЁЃ
СэЭтвЛИізіЗЈЃЌжЛЖСШызжЖЮbКЭЦфЖдгІЕФжїМќidЁЃПЩвдЯыЯѓЮЊетСНИізжЖЮЙЙГЩЕФНсЙЙЬхЃЌАДееbЕФжЕзїХХађЁЃХХађЭъГЩКѓЃЌАДзжЖЮbЕФЫГађвРДЮШЁжїМќidЃЌШЁЕУНсЙћЗЕЛиЁЃ
ЪЕМЪЩЯЕкЖўжжзїЗЈОЭЪЧетИіР§згжаЕФЪЕМЪжДааЙ§ГЬЁЃДцЗХгУгкХХађЕФзжЖЮжЕЕФНсЙЙЮвУЧГЩЮЊsort_keys.
жСгкorder by b,cетбљЕФгяОфЃЌаЇЙћгыorder by bЯрЭЌЃЌПЩвдМђЕЅРэНтЮЊЩЯУцНсЙЙЬхЖрСЫвЛИізжЖЮЁЃ
3ЁЂ зжЖЮКЏЪ§ХХађ
ЛЙЪЧАДЫГађЖСШыЫљгаЕФзжЖЮbЃЌжЛЪЧsort_keysжаДцЕФЪЧbЕФГЄЖШЖјвбЁЃ

4ЁЂ Order by rand()
АДеездШЛЯыЗЈЃЌ order by rand() вВПЩвдЗТееЩЯУцУшЪіЕФзіЗЈЃЌЖдгкУПвЛааЃЌНЋЩњГЩЕФrand()ЕФжЕЗХШыsort_kyesРяМДПЩЁЃЕЋЪЕМЪЩЯЩЯаЇЙћШчЯТЃК

ExtraзжЖЮРяУцгавЛИіUsing temporaryЃЌ вВОЭЪЧЫЕгУЕНСЫСйЪББэЁЃФЧУДUsing temporaryЕФЪБКђВйзїСїГЬЪЧдѕбљЕФФиЃП
a) ДДНЈвЛИіheapв§ЧцЕФСйЪББэЃЌзжЖЮУћЮЊ ”” a b c d, ЕквЛИізжЖЮЮЊФфУћ;
b) НЋБэtbжаЕФЪ§ОнАДааЖСШыЕНСйЪББэжаЃЌЭЌЪБИјЕквЛзжЖЮЬюШывЛИіЫцЛњЪЕЪ§(0,1);
c) АДееЕквЛИізжЖЮХХађЃЌЗЕЛи
d) ВщбЏЭъГЩЩОГ§СйЪББэ
ЗжЮівЛЯТетИіЙ§ГЬ,гЩгкАбЪ§ОнДгInnoDBБэРяУцЖСШыСйЪББэЃЌдђInnoDBБэЪЕМЪЩЯвВвбОЖСШыФкДцЃЌдкетИіЙ§ГЬжаЃЌШєВЛПМТЧФкДцВЛЙЛЪБЕФаДЮФМўВпТдЃЌ дђФкДцжагаСНЗнБэЕФШЋПНБДЃЛСэЭтЖрСЫДгФкДцжаНЋЪ§ОнвЛвЛПНБДЕНСйЪББэЕФЙ§ГЬЁЃ
етИіВщбЏдкВтЪдЛЗОГжаКФЪБ2.41sЃЈЖрДЮДЮжДааЃЌВЛМЦЕквЛДЮМгдиЪ§ОнЕФЪБМфЃЉ
order by rand()ЕФИФНј
ЪЕМЪЩЯЖдгкетжжМђЕЅЕФorder by rand() ЕФЧщПіЃЌвВПЩвдЕШЭЌгкАДееЗЧЫїв§зжЖЮРДДІРэЁЃдкsort_array жаДцШыЫцЛњжЕМДПЩЁЃ
АДееетИіЫМТЗЕФpatchдкетРяЃЌаЇЙћЩЯ

ЫЕУїЃКжДааЪБМфМѕЩйЮЊ1.89sЃЌадФмЬсЩ§21%, етИіР§згЕЅаа1kЃЌЕЅаадНДѓЬсЩ§аЇЙћдНКУЁЃ